
1. Chunk(청크)
1-1) 기본 개념
- Chunk 란 여러 개의 Item 을 묶은 하나의 덩어리(블록)
- 한번에 하나씩 아이템을 입력 받아 Chunk 단위의 덩어리로 만들고 Chunk 단위로 트랜잭션을 처리함 -> Chunk 단위로 Commit 과 Rollback 이 진행
- 일반적으로 대용량 데이터를 한번에 처리하는 것이 아닌 청크 단위로 쪼개어서 더 이상 처리할 데이터가 없을 때까지 반복
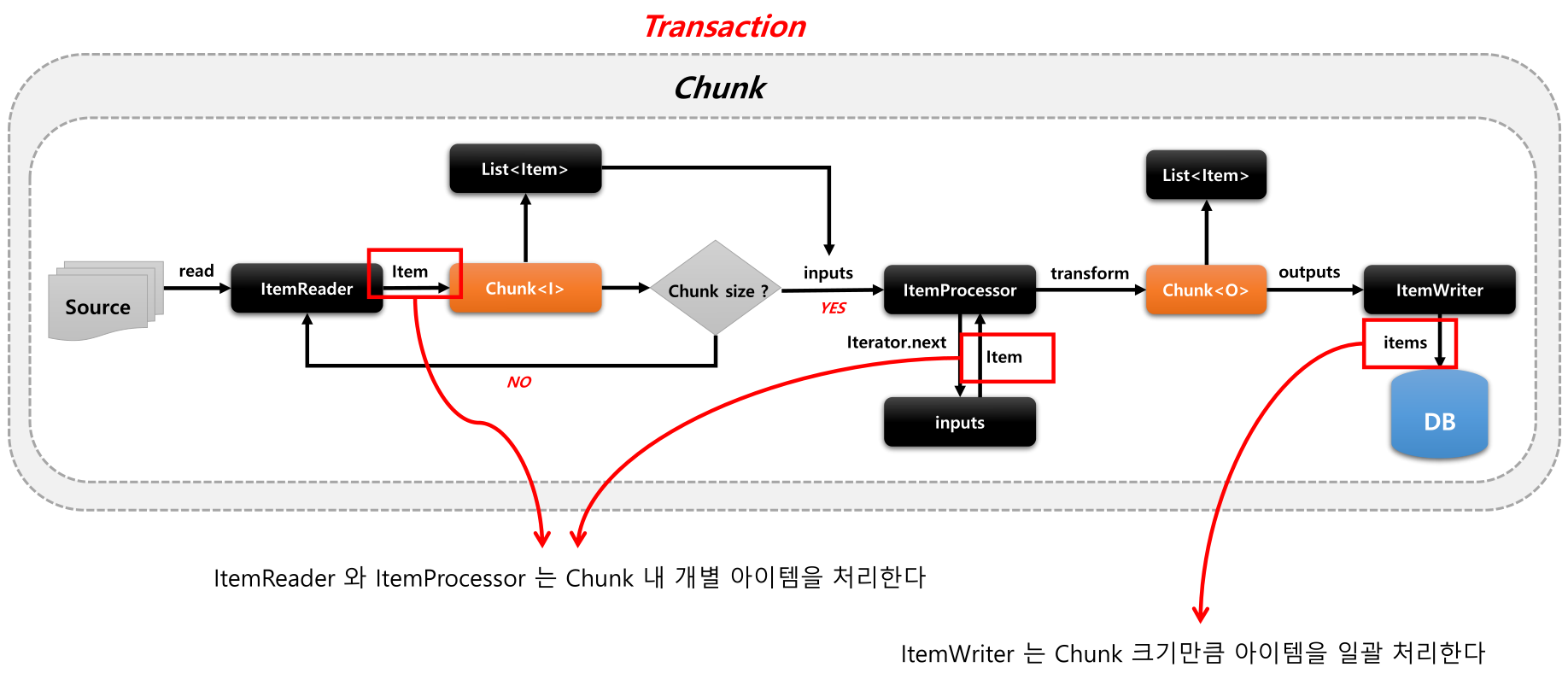
- Reader 와 Processor 에서는 1번의 수행이 이루어지고, Writer 에서는 Chunk 단위로 수행
for (int i =0; i< pageSize; i+=chunkSize) { // ChunkSize 단위로 묶어서 처리
List items = new ArrayList();
Object item = itemReader.read(); // Read 를 통해 데이터 조회
for (int j = 0; j < chunkSize; j++) { // ChunkSize 만큼 반복 Processor 처리
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items); // ChunkSize 만큼의 데이터를 한번에 처리
}- Chunk<I> VS Chunk<O>
- Chunk<I>
- ItemReader 로 읽은 하나의 아이템을 CHunk 에서 정한 개수만큼 반복해서 저장 - Chunk<O>
- ItemReader 로 부터 전달받은 Chunk<I> 를 참조해서 ItemProcessor 에서 적절하게 가공 후 ItemWriter 에 전달

1-2) 아키텍처
2. ChunkOrientedTasklet
2-1) 기본 개념
- Spring Bathc 에서 제공하는 Tasklet 구현체로 CHunk 지향 프로세싱을 담당하는 도메인 객체
- ItemReader, ItemWriter, ItemProcessor 를 사용해 Chunk 기반 데이터 입출력 처리 담당
- 내부적으로 ItemReader 를 핸들링 하는 ChunkProvider 와 ItemProcessor, ItemWriter 를 핸들링하는 ChunkProcessor 타입의 구현체를 가짐

2-2) API 정보

- Chunk 처리 중 예외가 발생하여 재시도할 경우 다시 데이터를 조회하는 것이 아니라 버퍼에 담아 놓았던 데이터를 조회
- chunkProvider.provide() 로 reader 에서 ChunkSize 만큼 데이터 조회
- chunkProcessor.process() 에서 reader 로 받은 데이터를 가공(Processor) / 저장(Writer) 수행
- Chunk 단위 입출력이 완료되면 버퍼에 저장한 Chunk 데이터 삭제
- 더이상 읽을 Item 이 없다면 Chunk 프로세스 종료
2-3) 기본 사용 구조
public Step chunkStep() {
return stepBuilderFactory.get("chunkStep")
.<I, O>chunk(10) // chunk size 설정, chunk size 는 commit interval 을 의미함, input, output 제네릭타입 설정
.<I, O>chunk(CompletionPolicy) // Chunk 프로세스를 완료하기 위한 정책 설정 클래스 지정
.reader(itemReader()) // 소스로 부터 item 을 읽거나 가져오는 ItemReader 구현체 설정
.writer(itemWriter()) // item 을 목적지에 쓰거나 보내기 위한 ItemWriter 구현체 설정
.processor(itemProcessor()) // item 을 변형, 가공, 필터링 하기 위한 ItemProcessor 구현체 설정
.stream(ItemStream()) // 재시작 데이터를 관리하는 콜백에 대한 스트림 등록
.readerIsTransactionalQueue() // Item 이 JMS, Message Queue Server 와 같은 트랜잭션 외부에서 읽혀지고 캐시할 것인지 여부, 기본값은 false
.listener(ChunkListener) // Chunk 프로세스가 진행되는 특정 시점에 콜백 제공받도록 ChunkListener 설정
.build();
}2-4) ChunkProvider / ChunkProcessor
- ChunkProvider
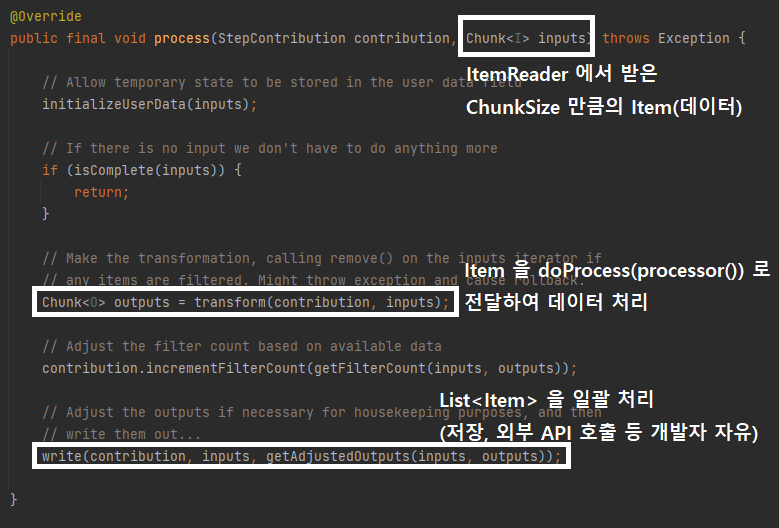
- ItemReader 를 사용해서 소스로부터 Item 을 ChunkSize 만큼 읽어서 Chunk 단위로 만들어 제공
- 내부적으로 반복문을 사용해서 ItemReader.read() 를 계속 호출하여 item 을 Chunk 에 쌓음
- 외부로부터 ChunkProvicer 가 호출될 때마다 항상 새로운 Chunk 가 생성 -> 여러 Job 들이 서로 Item 이 겹치지 않음
- 반복문 종료 시점
- ChunkSize 만큼 item 을 읽으면 반복문 종료 후 ChunkProcessor 수행
- ItemReader 가 읽은 item 이 Null 인 경우 Step 종료

- inputs 이 ChunkSize 만큼 쌓일 때까지 read() 를 호출
- read() 는 ItemReader.read 를 호출하여 데이터 조회

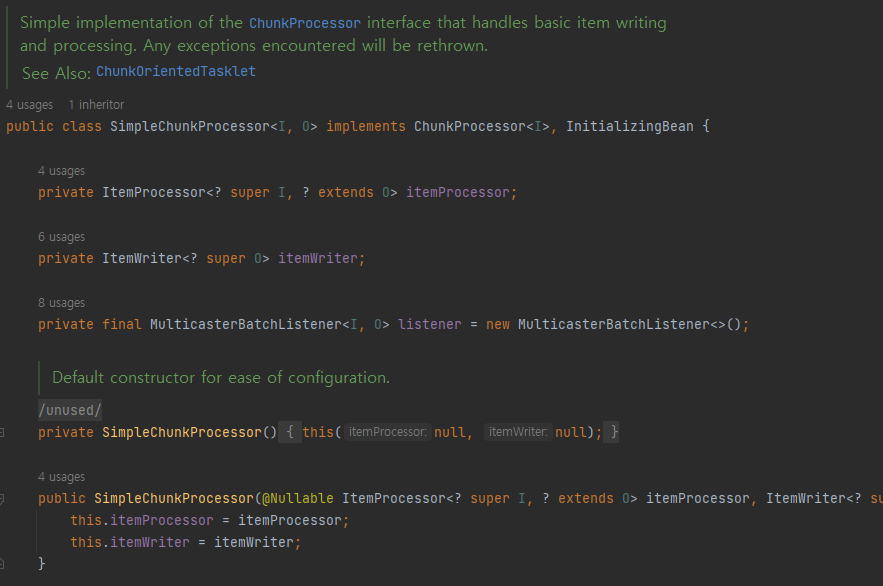
- ChunkProcessor
- ItemProcessor 를 사용하여 Item 을 처리(변형, 가공, 필터링 등)하고 ItemWriter 를 사용하여 Chunk 데이터를 저장, 출력
- 외부로부터 ChunkProcessor 가 호출될 때마다 항상 새로운 Chunk 가 생성
- ItemProcessor 처리가 완료되면 List<Item> 을 ItemWriter 로 전달
- ItemWriter 처리가 완료되면 Chunk 트랜잭션이 종료하게 되고 Step 반복문에서 다시 ChunkOrientedTasklet 이 새롭게 실행

- Processor 와 Writer 로직을 담당
- 인터페이스이기 때문에 실제 구현체가 필요(기본적으로는 SimpleChunkProcessor)
3. ItemReader / ItemWriter / ItemProcessor
3-0) Item
- 처리할 데이터의 가장 작은 구성 요소
- 예를 들면, 파일의 한줄 / DB의 한 Row / XML 의 특정 element 등
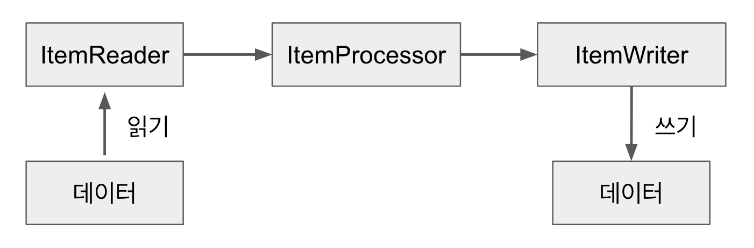
3-1) ItemReader
3-1-1) 기본개념
- 다양한 입력으로부터 데이터를 읽어서 제공하는 인터페이스 -> ex: DB, File, XML, JSON 등
- ChunkOrientedTasklet 실행 시 필수 설정
- 이외에도 Spring Batch 에서 지원하지 않는 Reader 가 필요할 경우 Custom 하여 Reader 생성 가능
3-1-2) 구현체

- ItemReader 는 다양한 구현체들이 구현 -> ex : JdbcPagingItemReader, JpaPagingItemReader, MybatisPagingItemReader 등
- 각 구현체들은 ItemReader 외에 ItemStream 인터페이스도 같이 구현
- 파일의 스트림을 열거나 종료, DB 커넥션을 열거나 종료, 입력 장치 초기화 등의 작업
- ExecutionContext 에 read 와 관련된 여러가지 상태 정보를 저장해서 재시작 시 다시 참조 하도록 지원
- 일부를 제외하고 하위 클래스들은 기본적으로 스레드에 안전하지 않기 때문에 병렬 처리시 데이터 정합성을 위한 동기화 처리 필요

- ItemReader 는 read() 메소드만 존재 -> read() 는 데이터를 읽어오는 메소드
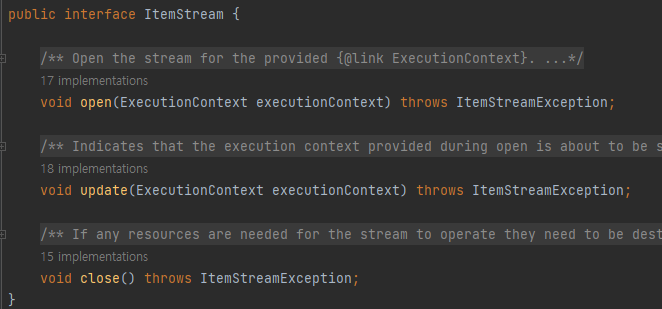
- ItemStream 은 주기적으로 상태를 저장핳고 오류가 발생하면 해당 상태에서 복원하기 위한 마커 인터페이스
- 배치 프로세스의 실행 Context 와 연계하여 ItemReader 상태를 저장하고 실패한 곳에서 다시 실행할 수 있게 해주는 역할
- ItemStream 은 3개의 메소드 존재 -> open(), close() 스트림을 열고 닫음 / update() Batch 처리의 상태를 업데이트
3-1-3) DB Reader(Ex : JpaAPagingItemReader)
@Bean(name = "JobParameterBatchReader")
@StepScope
public JpaPagingItemReader<Member> reader() {
log.info("ItemReader 에서는 데이터를 불러오는 로직 작성");
log.info("Param : " + jobParameter.getParam());
log.info("Date: " + jobParameter.getDate());
Map<String, Object> parameters = new HashMap<>();
parameters.put("code", "N");
return new JpaPagingItemReaderBuilder<Member>()
.name("JobParameterBatchReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("SELECT m FROM Member m WHERE m.code = :code")
.parameterValues(parameters)
.build();
}- 기본적으로 페이징 방식에서는 쿼리에 시작 행 번호(offset), 페이지 사이즈(pageSize0 를 지정
- Spring Batch 에서는 offset 과 limit 를 pageSize/fetchSize 설정 시 각 DB 와 쿼리에 알맞게 자동으로 생성
- entityManagerFactory
- JPA entityManagerFactory - pageSize
- 쿼리 상의 Row 의 Page(limit) 사이즈가 아닌 전체 조회 된 Row 수 안에서 최대 Limit 수 - queryString
- 수행할 쿼리 - parameterValues
- 수행할 쿼리에서 사용할 Parameter 정보
3-2) ItemWrtier
3-2-1) 기본 개념
- Chunk 단위로 ItemReader 로 부터 데이터를 받아 일괄 출력 작업을 하는 인터페이스
- Item 1개가 아닌 Item 리스트로 전달 받음
- ChunkOrientedTasklet 실행 시 필수 설정

- ItemReader 를 통해 각 항목을 개별적으로 읽고 이를 처리하기 위해 ItemProcessor 로 전달
- 해당 프로세스는 Chunk 의 Item 개수 만큼 처리될 때 까지 반복
- Chunk 단위만큼 처리가 진행되면 Wirter 에 전달되어 Writer 의 로직대로 일괄 처리
3-2-2) 구현체
- ItemReader 와 같이 다양한 구현제들이 존재
- 각 구현체들은 ItemWrtier 외에 ItemStream 인터페이스도 같이 구현

- Writer 에서는 항상 로직 이후 DB Session 관련하여 flush 진행
- Writer 가 받은 모든 Item 이 처리된 후, Spring Batch 는 현재 트랜잭션을 Commit
3-2-3) DB Writer(Ex: JdbcBatchItemWriter)
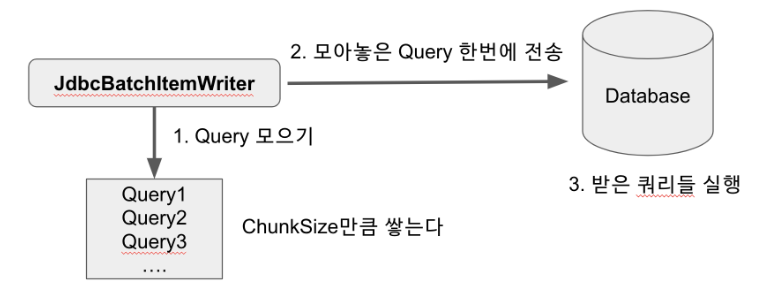
- 위 그림은 예시로 JDBC 의 Batch 기능을 사용하여 한번에 DataBase 로 전달하여 쿼리를 실행 -> 성능을 고려하여 다양한 방법으로 리팩토링 가능(업데이트를 일괄로 하여 DB 와 WAS 간의 왕복 횟수를 줄여 성능 향상 가능)
@Bean(name = "JobParameterBatchWriter")
@StepScope
public JdbcBatchItemWriter<Member> writer() {
log.info("ItemWriter 에서는 DB 저장과 같은 Transactional 한 로직 작성");
return new JdbcBatchItemWriterBuilder<Member>()
.assertUpdates(false)
.dataSource(dataSource)
.sql("UPDATE Member SET code = :code WHERE id = :id")
.beanMapped()
.build();
}- assertUpdate
- 적어도 하나의 항목이 행을 업데이트하거나 삭제하지 않을 경우 예외를 throw 할지 여부(기본값 true) - dataSoure
- DB Connection 정보 - sql
- 수행할 쿼리 sql - beanMapped
- 수행할 쿼리에서 사용할 Parameter 정보
3-3) ItemProcessor
3-3-1) 기본 개념
- 데이터를 출력(Writer)하기 전 데이터를 가공, 변형, 필터링하는 역할
- ItemReader 로 부터 넘겨받은 데이터를 각각 처리
- ItemProcessor 는 ChunkOrientedTasklet 실행 시 필수가 아님 -> Reader / Writer 와는 별도의 단계로 분리되었기 때문에 비지니스 로직을 분리할 수 있음

3-3-2) 구현체
- IteamReader / ItemWriter 와는 다르게 ItemStream 을 구현하지 않음
- 대부분 Custom 하여 사용하기 때문에 기본적으로 제공되는 구현체가 적음
3-3-3) 기본 사용법
- 일반적으로 ItemProcessor 를 사용하는 방법은 2가지
- 변환
- Reader 에서 읽은 데이터를 원하는 타입으로 변환해서 Writer 로 전달 - 필터
- Reader 에서 넘겨준 데이터를 Writer 로 넘겨줄 것인지 결정
- null 을 반환(전달)하면 Writer 에 전달되지 않음
- ItemProcessor 는 추상메소드가 1개이므로 람다식을 사용할 수 있음
@Bean(name = "JobParameterBatchProcessor")
@StepScope
public ItemProcessor<Member, Member> processor() {
log.info("ItemProcessor 에서는 데이터를 처리 하는 로직 작성");
return item -> {
if("N".equals(validDate(jobParameter.getDate()))) {
return null;
}
return item;
};
}- ItemProcessor<Member, Mebmer>
- Reader 에서 읽어올 타입이 Member(좌측) 이고, Writer 로 넘겨줄 타입이 Member(우측) - return null;
- Writer 에 Item 을 넘기지 않음
4. 아키텍처


참고
- https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B0%B0%EC%B9%98/dashboard
'BackEnd > Spring Batch' 카테고리의 다른 글
| [Spring Batch 정리하기] 6. Listener (0) | 2024.08.06 |
|---|---|
| [Spring Batch 정리하기] 4. 실행하기 (0) | 2024.07.29 |
| [Spring Batch 정리하기] 3. 도메인 (1) | 2024.07.25 |
| [Spring Batch 정리하기] 2. DB Schema (0) | 2024.07.22 |
| [Spring Batch 정리하기] 1. Spring Batch 개요 (0) | 2024.07.17 |
