
1. EXISTS 절
- 결과로 TRUE, FALSE 를 반환하는 연산자.
- 한 테이블이 다른 테이블과 외래키(FK)와 같은 관계인 경우 유용합니다.
- 조건에 해당하는 ROW의 존재 유무 이후 더 수행하지 않는다.
- 즉, 테이블 간의 결과를 어떤 값이 존재하는 지만 조회 할때 사용합니다.
- 쿼리의 의도롤 고려했을 대 EXISTS 가 IN 에 비해 성능이 좋습니다.(그렇지 않을 경우, JOIN 활용)
EXIST
- 메인 쿼리 -> EXISTS 쿼리 순서로 진행
-- 기본 구문
SELECT
*
FROM
table
WHERE
[NOT] EXISTS(subquery);1-1. 예제
- 아래와 같이 간단하게 데이터를 만들고 확인해보겠습니다.
SELECT * FROM STUDENT_TABLE;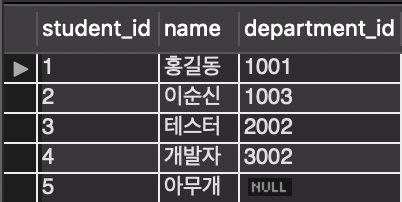
SELECT * FROM DEPARTMENT_TABLE;
- EXISTS 절을 사용하여 두 개의 테이블 중 조건에 맞는 ROW 들만 추출합니다.
SELECT
*
FROM STUDENT_TABLE A
WHERE
EXISTS (SELECT 1
FROM DEPARTMENT_TABLE B
WHERE A.department_id = B.department_id)
;
- 반대로 조건에 맞지 않는 ROW 들만 추출하고자 한다면 앞에 NOT EXISTS 절을 사용합니다.
SELECT
*
FROM STUDENT_TABLE A
WHERE
NOT EXISTS (SELECT 1
FROM DEPARTMENT_TABLE B
WHERE A.department_id = B.department_id)
;
2. IN 절
- 집합 내부에 값이 존재하는지 여부를 확인합니다.
- 존재하는 데이터의 값을 비교하기 때문에 EXISTS 절보다 속도가 느린 경우가 존재합니다.
- 조건의 범위를 지정하는데 사용합니다.
IN
- IN 쿼리 -> 메인 쿼리 순서로 진행
-- 기본 구문
SELECT
*
FROM
table
WHERE
something [NOT] IN ("", "", "" ...);
-- 서브 쿼리
SELECT
*
FROM
table
WHERE
something [NOT] IN (select something from table2);참고!!!
NOT IN에 경우에 조건에 맞는 데이터가 있어도 중간에 NULL이 존재하게되면 no rows selected가 나오게 되니 NVL 처리로 NULL 처리를 해야합니다.
2-1. 예제
- 아래와 같이 간단하게 데이터를 만들고 확인해보겠습니다.
SELECT * FROM STUDENT_TABLE;
SELECT * FROM DEPARTMENT_TABLE;
- IN 절을 사용하여 테이블 중 조건에 맞는 데이터 들만 추출합니다.
SELECT
*
FROM STUDENT_TABLE A
WHERE
department_id IN ('1001', '2002', '3002')
;결과 사진
- NOT IN 절 사용 시 STUDENT_TABLE 에 NULL 값이 포함되어 있기 때문에 검색시 no rows selected 가 발생합니다.
SELECT
*
FROM STUDENT_TABLE A
WHERE
department_id NOT IN (SELECT department_id FROM DEPARTMENT_TABLE)
;결과 사진
- NVL 처리하여 정상적으로 조회되도록 수정합니다.
SELECT
*
FROM STUDENT_TABLE A
WHERE
department_id NOT IN (SELECT NVL(department_id, '0000') FROM DEPARTMENT_TABLE)
;결과사진
3. 비교
- 보통 연산자를 사용하는 쿼리에서는 IN 절보다 EXISTS 절을 사용하는 쿼리가 성능이 좋습니다.
- EXISTS 절은 "at least found(최소 발견???)" 원칙에 따라 작동함에 따라, 일치하는 행이 발견되면 테이블 스캔을 중지합니다.
- 반면에, IN 절은 하위 쿼리와 결합하게 되면 MySQL은 서브 쿼리를 먼저 처리한 다음 서브 쿼리의 결과를 가지고 다시 메인 쿼리를 처리합니다.
- 그렇기 때문에, 일반적으로 서브 쿼리에 데이터가 많이 포함되어 있으면 EXISTS 절이 더 좋은 성능을 제공하고, 데이터가 적거나, 작은 연산자를 사용하는 쿼리에 대해서는 IN 절이 더 좋은 성능을 제공하게 됩니다.
참고
'BackEnd > DataBase' 카테고리의 다른 글
| [DB] NoSQL DataBase 정리 (2) | 2022.11.12 |
|---|---|
| [MySQL] DATEDIFF, TIMESTAMPDIFF 함수를 통한 날짜 차이 계산하기 (2) | 2022.08.29 |
| [MySQL] abs 함수를 통한 절대값 구하기 (0) | 2022.08.26 |
| [DB] DELETE 쿼리 시 Join 사용하기(MySQL) (0) | 2022.07.20 |
| [MySQL] on duplicate key update(Insert 시 값 존재하면 Update) (0) | 2022.07.01 |
